
Having had studied Machine Learning and Neural Networks for a long time, I no longer think of the movie when I hear the word “transformers”. Now, when I hear CNN, I no longer think of the news channel. So, I had a confusing conversation with my Social Sciences friend, when she said that CNN was biased, and I asked if her dataset was imbalanced. Nevertheless, why are we talking about this?

Before I learned about Neural Networks, I always wondered as to how computers could even “look” at images, let alone, tell us something about that image. Then, I learned about Convolutional Neural Networks, or CNNs! They work by sliding a small “window” across an image, while trying to make sense of the pixels that the window sees. As the CNN trains on images, it learns how to pick out edges and shapes that help it make sense of images down the line. For almost a decade, the best performing image models relied on convolutions. They are designed to do very well with images due to their “inductive bias” or “expertise” on images. These sliding window operations make it suitable to detect patterns in images.
Transformers, on the other hand, were designed to work well with sequences of words. They take in a sequence of encoded words and can perform various tasks with them, such as language translation, sentiment analysis etc. However, they are so versatile that, in 2020, they were shown to outperform CNNs on image tasks. How the heck does a model designed for text even work with images you might ask! Well, you might have heard of the saying, “an image is worth a 1000 words.” But in 2020, Dosovitskiy et al. said “An image is worth 16×16 words”. In this paper, they cut up an image into patches of 16×16 pixels. Pixels from each patch were then fed into a transformer model as if each patch were a word from a text. On training this model on millions of images, it was found that it outperformed CNNs, even though it does not have that inductive bias! Essentially, it learns to look at images by looking at a lot of images.
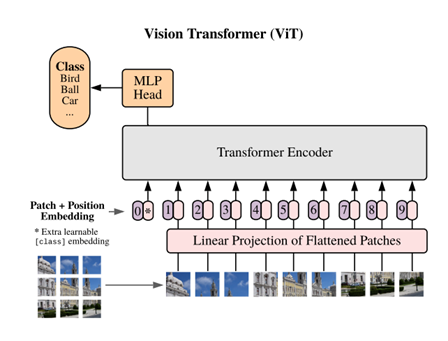
Now, just like the Transformers franchise, a new paper on different flavors of vision transformers drops every year. And just as the movies in the franchise take a lot of money to make, transformers take a lot of data to train. However, once pretrained on enough data, they can smash CNNs out the park when further finetuned on small datasets like those common in medical imaging.
Now let’s use transformers in a sentence…
Serious: My pretrained vision transformer finetuned to detect infiltration in these chest X-Ray images, outperformed the CNN.
Less Serious: I have 100,000 images, that’s enough data to train my Vision Transformer from scratch! *Famous last words*
See you in the blogosphere!
Manav Shah