Well, if you are relaxed and heading nowhere in particular then I guess you probably won’t be too concerned with showing causality either. In our past few posts we have been discussing Bradford Hill’s criteria for determining causality (see Strength and Consistency for a refresher). If you are stressed out already, have a listen to “Come the morning” from an up and coming Canadian artist from Winnipeg, Manitoba – Sebastian Owl – before reading on.
Today we will talk about the third of the nine Hill criteria: Specificity
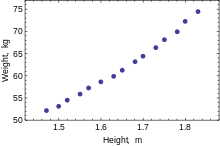
When considering the specificity of the association of interest, we wish to establish whether a single putative cause produces a specific effect. When specificity of an association is found, it provides additional support for a causal relationship. But keep in mind that very often the effect under investigation may have more than one cause. So the absence of specificity in no way negates a causal relationship. This criterium of Hill’s is considered to be the least important and can often be over-ruled in the case of multi-causal relationships.
Next, post we will talk about the oh-so-important criterium: temporality.
If you are nowhere in particular then you are not being specific to your whereabouts – right? Anyway, why don’t you watch this great Film festival short by Mason Cardiff, Nowhere in particular, to decompress and…
… I’ll see you in the blogosphere.
Pascal Tyrrell
Next, post we will talk about the oh-so-important criterium: temporality.
If you are nowhere in particular then you are not being specific to your whereabouts – right? Anyway, why don’t you watch this great Film festival short by Mason Cardiff, Nowhere in particular, to decompress and…
… I’ll see you in the blogosphere.
Pascal Tyrrell