
 |
| Poster to be presented at the Department of Medical Imaging Resident Achievement Day 2016 |
Where have a I been you ask? At my desk putting this program together! I apologize for being MIA for the past month or so but I it has been a busy time nurturing this fledgling program of MiNE (pun intended!).
Here is the premise:
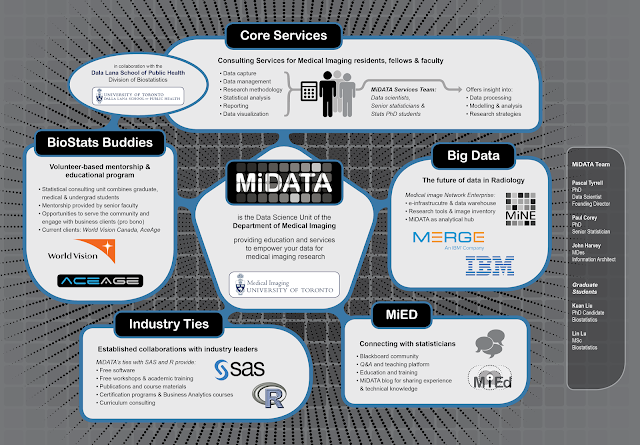
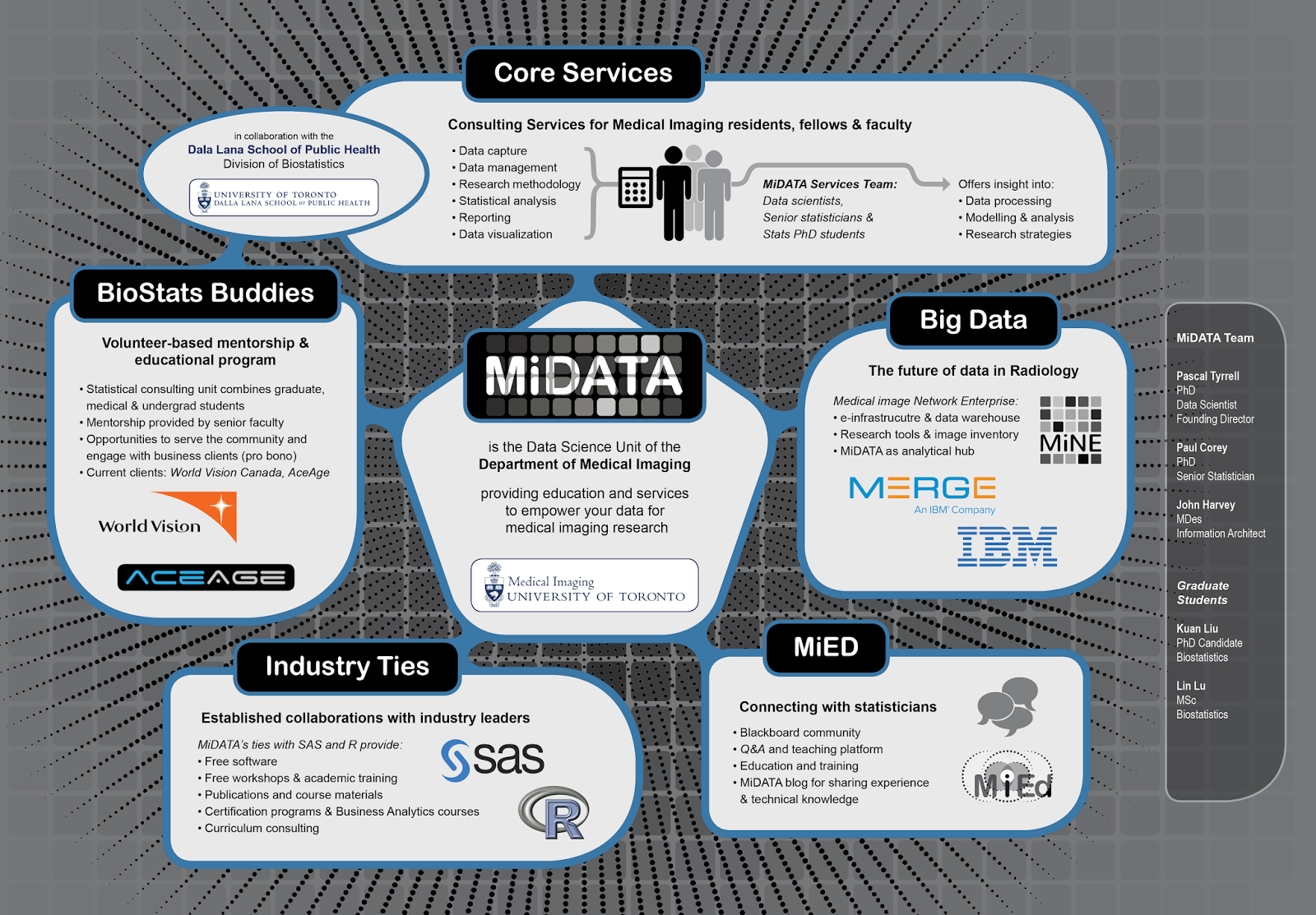
Bridging the gap between clinical expertise and the science of managing and analyzing medical imaging data is challenging. To provide direction for data management as well as the analysis and reporting of research findings, we are in the process of introducing a data science unit – MiDATA – offering users an environment geared towards a “soup to nuts” approach to medical imaging research methodology and statistics. The Department of Medical Imaging of the University of Toronto is one of the largest in North America with a clinical faculty of more than 184 faculty, 60 residents and 80 fellows based at nationally and internationally renowned hospitals conducting cutting edge clinical research in the greater Toronto area. The challenge of any successful research and educational program is bridging the “know-do” gap. The goal of MiDATA is to facilitate impactful research through the efficient and creative use of a mentored learning environment.
Shout out to our collaborators the Division of Biostatistics from the Dalla Lana School of Public Health!
Tomorrow is the official unveiling at the 2016 Department of Medical Imaging Resident Achievement Day. I thought I would share with you our poster as a sneak peek…















