Hi everyone! My name is Linxi Chen and I’m finishing my third year at the University of Toronto, pursuing a statistics specialist and a mathematics major. I did an STA399 research opportunity program with Professor Pascal Tyrrell from May 2021 – August 2021 and I am very grateful that I can have this opportunity. This project provided me an opportunity in understanding machine learning and scientific research. I would love to share my experience with you all.
Initially, I had no experience with machine learning and convolutional neural network and integrating machine learning with medical imaging was a brand-new area for me. Therefore, at the beginning of this project, I searched loads of information on machine learning to gain a general picture of this area. The first assignment in this project was to make a slide deck on machine learning in medical imaging. Extracting and simplifying the gathered information helped me understand this area more deeply.
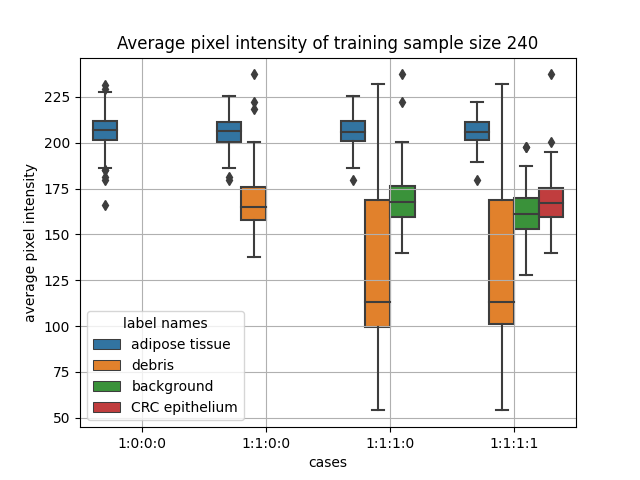
My research project is to find out an objective metric for heterogeneity and explore how dataset heterogeneity will affect heterogeneity as measured by the CNN training image features with sample size. At first, how to specifically define the term “heterogeneity” was a big challenge for me, since there are various kinds of definitions on Google and there was so little information that was directly related to my project. By comparing the information on websites and talking with Professor Tyrrell in the weekly meeting, I managed to define the term “between-group heterogeneity” as the extent to which the measurements of each group vary within a dataset, considering the mean of each subgroup and the grand mean of the population. Next, designing the experiment setup was also challenging, because I have to ensure the experiment steps are applicable and explicable. The datasets were separated into different groups according to the label of each image. We introduced new groups into the dataset while keeping the total sample size the same in each case. There was a total of four cases and the between-group heterogeneity was measured using Cochran’s Q which is a test statistic based on chi-squared distribution. The experiment setup was modified several times, because problems came up from time to time. For example, I planned to use multi-classification CNN model at first, but it showed that I have to use different number of output neurons for the model in different cases, which made the results not comparable. Professor Tyrrell and Mauro suggested I use a binary-classification model with pseudo label, which successfully solved this problem. Luckily, I found some code on the website and with the help of Mauro, I managed to come up with the code that was applicable to use. Next came the hardest part that I encountered. Although idealistically my expectation could be explained very well, still the output results I got were not what I expected. After modifying the model and the sample size several times, I finally managed to get the expected results.
Overall, I have learned a lot from this ROP program. With the guidance of Professor Tyrrell and the help of students in the lab, I have gained an in-depth understanding of machine learning, neural network and the process of scientific research. Also, I have become more familiar with writing a formal scientific research paper. The most valuable thing that I got from this experience is the ability of problem-solving and never be frustrated when things get wrong. I would like to thank Professor Tyrrell for giving me this opportunity to learn about scientific research and helping me overcome all the challenges that I encountered during this process. I’m very grateful that I have gained so many valuable skills in this project. Also, I would like to thank Mauro and all the members in the lab for giving me so much help with my project.
Linxi Chen