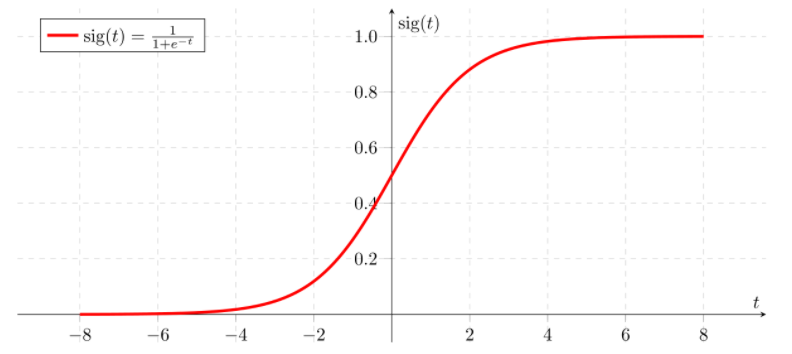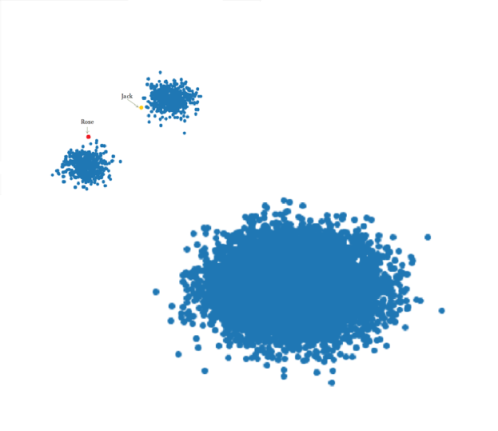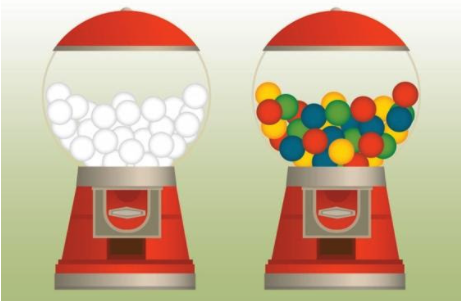
Today we are going to talk about the variation within a dataset, which is different from the term “pure variance” that we commonly use. So, what exactly is heterogeneity?
There are three different kinds of data heterogeneity within the dataset: clinical heterogeneity, methodological heterogeneity, and statistical heterogeneity. Inevitably, the observed individuals in a dataset will differ from each other, which from the perspective of medical imaging, a set of images might be different from the average pixel intensities, RGB values, border on the images, and so on. Therefore, any kind of variability within the dataset is likely to be termed heterogeneity.
However, there are some differences between variance and heterogeneity. If a population has lots of variance, it only means that there are a lot of differences between the grand mean of the population and the individuals. Variance is a measure of dispersion, meaning how far a set of numbers is spread out from their average value. However, with respect to data heterogeneity, it means that there are several subpopulations in a dataset, and these subpopulations are disparate from each other. Therefore, we consider the between-group heterogeneity which represents the extent to which the measurements of each group vary within a dataset, considering the mean of each subgroup and the grand mean of the population.
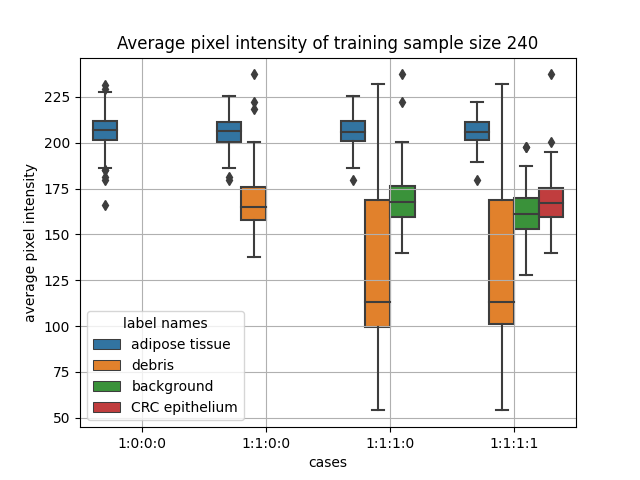

For example, if we are studying the height of a population, it is expected that the height of people from different regions (e.g., north, south, east, west of Canada) will be disparate from each other. If we separate the population into groups according to the region, we can calculate heterogeneity by measuring the variation of height between each group. If a population has a high value of heterogeneity, it will cause some problems to model training, causing a low testing accuracy.
Now for the fun part, using heterogeneity in a sentence by the end of the day!
Serious: The between-group heterogeneity in the training dataset made some negative impacts to the model training and therefore resulted in low testing accuracy.
Less serious: Today’s dinner was so wonderful! We had stewing beef, fried chicken, roasted lamb, and salads. There is so much heterogeneity in today’s dinner!
See you in the blogosphere!
Linxi Chen