You might be thinking, “KL Divergence? Sounds exotic. Is it something to do with the Malaysian capital (Kuala Lumpur) or a measurement (kiloliter)?” Nope, and nope again! It stands for Kullback-Leibler Divergence, a fancy name for a metric to compare two probability distributions.
But why not just compare their means? After all, who needs these hard-to-pronounce names? Kullback… What was it again? That’s a good point! Here’s the catch: two distributions can have the same mean but look completely
different. Imagine two Gaussian distributions, both centered at zero, but one is wide and flat, while the other is narrow and tall. Clearly, not similar!
So, maybe comparing the mean and variance would work? Excellent thinking! But what if the distributions aren’t both Gaussian? For example, a wide and flat Gaussian and a uniform distribution (totally flat) might look similar visually, but the uniform distribution is not parametrized by a mean or variance. So, what do we compare?
Enter KL Divergence!
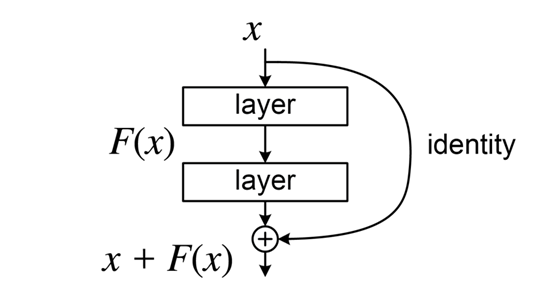
KL Divergence returns a single number that tells us how similar two distributions are, regardless of their types. The smaller the number, the more similar the distributions. But how do we calculate it? Here’s the formula (don’t worry, you don’t have to memorize it!).

Notice, if the distribution q has probability mass where p doesn’t, the KL Divergence will be large. Good, that’s what we want! But, if q has little mass where p has a lot, the KL Divergence will be small. Wait, that’s not what we want! No, it’s not, but luckily KL Divergence is asymmetric! KL(q || p) returns a different value than KL(p || q), so
we can compute both! Why are they different? I’ll leave that up to you to figure out!
KL Divergence in Action
Now, the fun part: using KL Divergence in a sentence!
Serious: Professor, can we approximate one distribution with another by minimizing the KL Divergence between them? That’s a great question! You’ve just stumbled on the idea behind Variational Inference.
Less Serious: Ladies and gentlemen, the KL Divergence between London and Kuala Lumpur is large, and so our flight time today will be 7 hour and 30 minutes. Please remember to stow your hand luggage in the overhead bins above you, fold your tray tables, and fasten your seatbelts.
See you in the blogosphere,
Benedek Balla