
Hi! My name is Paul Tang and I just finished my second year at UofT studying computer science specialist and cognitive science major. During this summer, I enrolled in STA299 under the supervision of Prof. Pascal Tyrrell to learn how to conduct research, and I will be sharing my experience in this reflection blog post.
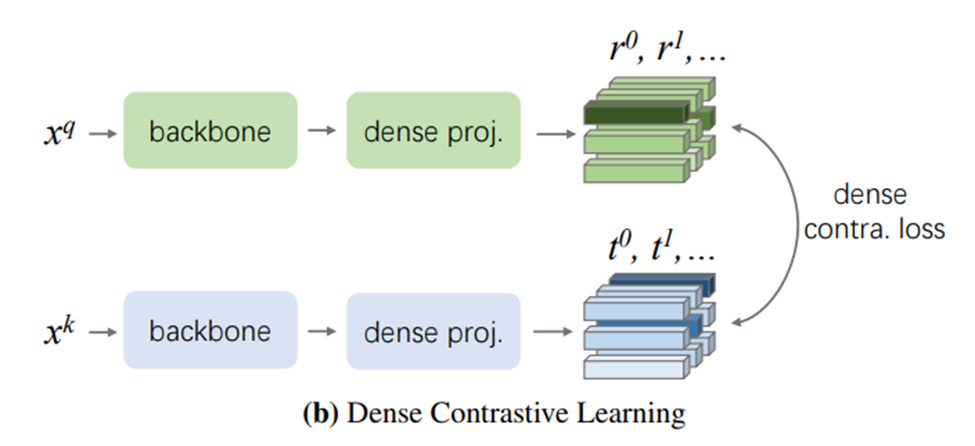
The first phase of my ROP experience concerns formulating a research question. Having a keen interest in machine learning, I got my inspiration for combining it with my research from a weekly lab meeting where Mauro presented his graduate research work (on the generation of synthetic ultrasound image data). I decided to focus on the problem that the amount of annotated data in the field of medical imaging is often limited for effective supervised training. Eventually, by reading papers and discussing my ideas with Prof. Tyrrell during the first few weeks, the solution I decided on was to use self supervised learning to pretrain a machine learning model for improving its performance. In particular, I chose the contrastive learning based self supervised learning method called DenseCL. Luckily, I got my data right at the lab using the ultrasound knee recess distension dataset for semantic segmentation. My ROP project dealt with comparing the effect of using DenseCL pretraining on the segmentation performance.
At first, I was doubtful of my research question: afterall, many papers I read already showed using self supervised pretraining did improve task performance, so wouldn’t my research be too “obvious”? However, I realized along the way that some interesting gaps still existed (e.g. current self supervised pretrain methods used in the domain of medical images do not extract local image features, which could be helpful for segmentation tasks), and these gave me confidence and excitement for my research.
Getting to work, I first identified the github repositories I would use in my project. Setting up the environment and the repositories to work with my dataset took much longer than expected (in fact, I had to switch to a different github repository due to “false advertising” from the original one), and I learned that checking with lab members (Mauro, Atsuhiro) and asking for ideas when starting to work on anything could save much needed time. I made several mistakes while training my models. When I first obtained the performance result (mIoU) from my segmentation model, I was relieved that it was consistent with previous results obtained in the lab. However, using this model in another experiment produced highly untypical results, which led me back to debug the model. Eventually the problem was found to be due to small batch size. Although this mistake cost me much training time, it did allow me to explore and gain familiarity with the configurations of a machine learning model, which I find very rewarding.
Eventually, I obtained results that show a small performance improvement in using DenseCL pretraining for the segmentation of ultrasound knee distention images. My project still had its limitations: my result was not statistically rigorous as I didn’t account for randomness in the training process. Furthermore, the amount of images I used for DenseCL pretraining is much fewer than what would typically be used in a self supervised learning setting. These limitations served as great motivation for further research.
This research experience taught me how humbling doing research was: many things I took for granted require careful testing, and that many gaps still exist in the current literature upon closer inspection. I am thankful to Prof. Tyrrell’s openness for allowing us to choose our own research questions, and I am thankful to all the help the lab members (especially Mauro and Atsuhiro) provided to me.
Paul Tang